
The attention mechanism is becoming increasingly popular in Natural Language Processing (NLP) applications, showing superior performance than convolutional and recurrent architectures. However, general-purpose platforms such as CPUs and GPUs are inefficient when performing attention inference due to complicated data movement and low arithmetic intensity. Moreover, existing NN accelerators mainly focus on optimizing convolutional or recurrent models, and cannot efficiently support attention. In this paper, we present SpAtten, an efficient algorithm-architecture co-design that leverages token sparsity, head sparsity, and quantization opportunities to reduce the attention computation and memory access. Inspired by the high redundancy of human languages, we propose the novel cascade token pruning to prune away unimportant tokens in the sentence. We also propose cascade head pruning to remove unessential heads. Cascade pruning is fundamentally different from weight pruning since there is no trainable weight in the attention mechanism, and the pruned tokens and heads are selected on the fly. To efficiently support them on hardware, we design a novel top-k engine to rank token and head importance scores with high throughput. Furthermore, we propose progressive quantization that first fetches MSBs only and performs the computation; if the confidence is low, it fetches LSBs and recomputes the attention outputs, trading computation for memory reduction. Extensive experiments on 30 benchmarks show that, on average, SpAtten reduces DRAM access by 10.0x with no accuracy loss, and achieves 1.6x, 3.0x, 162x, 347x speedup, and 1,4x, 3.2x, 1193x, 4059x energy savings over A3 accelerator, MNNFast accelerator, TITAN Xp GPU, Xeon CPU, respectively.
The model size and computation of NLP models are increasing exponentially. That requires innovations across the full stack, from algorithm to hardware. Our goal is to push the frontier of green, environmental friendly and sustainable NLP by reducing the model inference and training cost, and democratize NLP by enabling them on affordable low-end hardware devices which are accessible to all people. Specifically, the HAT Hardware-Aware Transformer NAS proposes an efficient NAS framework to search for specialized models for target hardware platforms with hardware feedback (e.g., energy, latency) in the loop. Lite Transformer proposes a new hybrid convolution-attention operation. SpAtten is an algorithm-hardware co-design accelerator with support of token and head pruning and progressive quantization. It accelerates NLP models by removing sentence redundancy. MicroNet compression experiments with weight pruning and quantization of language models. SpArch accelerator accelerates sparse matrix multiplications for sparse FC in NLP layers by jointly optimizing input and output data reuse.

The attention mechanism is becoming increasingly popular in Natural Language Processing (NLP) applications, showing superior performance than convolutional and recurrent architectures. However, general-purpose platforms such as CPUs and GPUs are inefficient when performing attention inference due to complicated data movement and low arithmetic intensity. Moreover, existing NN accelerators mainly focus on optimizing convolutional or recurrent models, and cannot efficiently support attention. SpAtten is an efficient algorithm-architecture co-design that leverages token sparsity, head sparsity, and quantization opportunities to reduce the attention computation and memory access. Inspired by the high redundancy of human languages, we propose the novel cascade token pruning to prune away unimportant tokens in the sentence. We also propose cascade head pruning to remove unessential heads. Cascade pruning is fundamentally different from weight pruning since there is no trainable weight in the attention mechanism, and the pruned tokens and heads are selected on the fly. To efficiently support them on hardware, we design a novel top-k engine to rank token and head importance scores with high throughput. Furthermore, we propose progressive quantization that first fetches MSBs only and performs the computation; if the confidence is low, it fetches LSBs and recomputes the attention outputs, trading computation for memory reduction. Extensive experiments on 30 benchmarks show that, on average, SpAtten reduces DRAM access by 10.0x with no accuracy loss, and achieves 1.6x, 3.0x, 162x, 347x speedup, and 1,4x, 3.2x, 1193x, 4059x energy savings over A3 accelerator, MNNFast accelerator, TITAN Xp GPU, Xeon CPU, respectively.

Remove redundant tokens and heads with cumulative importance scores, thus reducing computation and DRAM access.

More visualizations and examples on how tokens are pruned based on attention probabilities.
On discriminative BERT Model:



On generative GPT-2 Model:


The SpAtten architecture is equipped with specialized piplined datapath and operators for high throughput and energy efficiency.

SpAtten has more than 100x speedup over server-level GPU and CPU, more than 1000x speedup over edge devices, and 1.6x to 3x speedup over previous state-of-the-art accelerators.

22x speedup is from specialized datepath, 3.4x from pruning techniques, and 2.8x from progressive quantization.

Hanrui Wang, Zhanghao Wu, Zhijian Liu, Han Cai, Ligeng Zhu, Chuang Gan, Song Han
ACL 2020 Paper / Slides / Video / Code / Project Page
HAT NAS framework leverages the hardware feedback in the neural architecture search loop, providing a most suitable model for the target hardware platform.

The results on different hardware platforms and datasets show that HAT searched models have better accuracy-efficiency trade-offs.

Zhanghao Wu, Zhijian Liu, Ji Lin, Yujun Lin, Song Han
ICLR 2020 Paper / Slides / Code / Project Page
Lite transformer designs Long-Short Range Attention (LSRA) with attention and convolution as two branches

The results on different datasets show that LSRA-based searched models have better accuracy-efficiency trade-offs.

Zhekai Zhang*, Hanrui Wang*, Song Han, William J. Dally (* Equal Contributions)
HPCA 2020 Paper / 2-min Intro / Intro / Talk / Slides / Project Page
SpArch accelerator accelerates sparse matrix multiplications by joinly optimizing input and output data reuse.
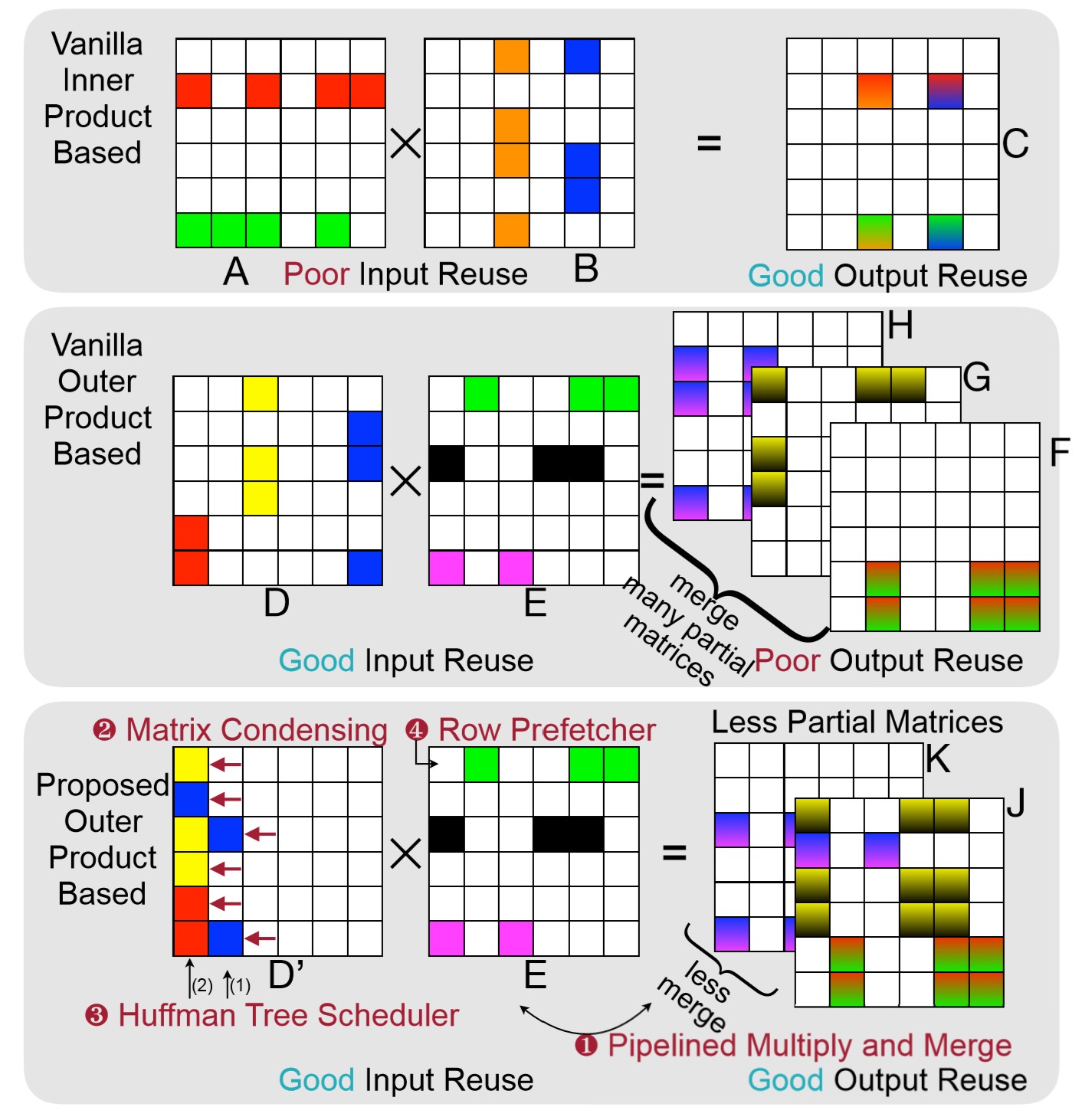
It achieves several orders or magnitude better performance and energy efficiency than other hardware platforms.

Zhongxia Yan, Hanrui Wang, Demi Guo, Song Han
JMLR 2020 Paper / Code / Talk / Project Page
NLP Micronet experiments on weight pruning and quantization of lanauge models. It reduces the model size by more than 41x and won the champion of NeurIPS 2019 MicroNet efficient NLP challenge. The goal of the challenge is to design a model with smallest possible size and computation while achieving lower than 35 perplexity.

A3, MNNFast, GOBO, Q-BERT, TernaryBERT, BinaryBERT, DeFormer, EdgeBert, Pay Less Attention, AdaBert, DeeBert, Longformer, Sparse Transformer, etc.
@inproceedings{wang2021spatten,
title={Spatten: Efficient sparse attention architecture with cascade token and head pruning},
author={Wang, Hanrui and Zhang, Zhekai and Han, Song},
booktitle={2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA)},
pages={97--110},
year={2021},
organization={IEEE}}



